GDPR and the Right to be Forgotten


Recently I’ve been having more and more conversations around GDPR, and specifically the Right to be Forgotten portion of the regulation.
So if we have a customer that asks to be forgotten, how do we deal with that? And what does that mean within our Clarify/Dovetail systems?
Often, the conversations dive into what data do we need to get rid of.
Customer Information
In our CRM / case management systems, the customer record is pretty contained. We have the contact table for the person itself, which has the person’s name, phone number, email address, etc. And we have the e_addr table, for their additional phone numbers, email addresses, and web sites.
There’s some slight differences if we’re dealing with B2C or B2B organizations. With B2C, where we might be dealing with Individual Contacts, we may also need to deal with the related site and address records.
Notes, Emails, Cases
But then we have all of our workflows and interactions with the customer – which may contain customer data. Notes and emails for the contact themself. And of course – Cases – especially case notes and case emails that may contain sensitive or identifying customer data.
And then the conversation tends to lead to a couple of different avenues of how to deal with this data.
The most common approaches seem to be either to delete or to redact the information.
Delete
Deleting the customer record (and related data) seems to be the most common approach. We can delete the contact and related e_addr records. If it’s an individual contact (in a B2C environment), we might also delete the contact_role, site, and address records.
But, we also have to deal with the cases. Case notes and case emails likely contain sensitive or identifying customer data.
Deleting the data seems to be the go-to choice – but I think it yields some pitfalls as well. If you delete the customer’s cases – you’ve now affected your history and reporting.
If we delete cases, we then lose visibility into not only the cases themself, but related KPIs. We no longer have accurate counts for:
- number of cases created, timing, and frequency
- cases broken down by case type, severity, part, or business unit
- cases worked by an individual user
- SLA measurements
- per-incident contract reporting
- etc.
We spend so much time making sure we collect the data so that we can use it – it seems odd to want to throw it away.
Depending on the number of GDPR requests received, this may or may not have a significant impact on reporting and analytics.
Redact
Instead of deleting the data, we can redact it instead. We can fine-tune our redacting, so that we only redact sensitive or identifying customer data. Obviously, things like customer name, phone numbers, email addresses, addresses, etc.
When we look at our workflow objects (such as Cases) – we can redact certain pieces of data – where we have identifying customer data – and keep the rest intact. For example, we’d likely redact anything that is a text or notes field – where customer data may be present. This would include the case title, notes, emails, phone logs, etc. But we can maintain the case identifying information – case type, severity, the related part and serial number, all of the user and system workflow actions, create and close history items, etc. This allows us to maintain the important data that we collect and use for both historical and future analytic purposes.
Deleting with DIET
I’ve talked many times in the past about the power of the Dovetail DIET (ArchiveManager) tool.
We can use DIET to delete (purge) data from the database.
DIET uses directive files, which direct DIET in what to purge, and how to traverse and deal with related data.
For example, when purging a case, we want to purge
- the case itself
- all related notes logs, phone logs, email logs, and research logs
- all close case records
- all activity logs
- all time and expense logs
- all commitments
- etc.
DIET ships with example directive files that handle all of this.
If you don’t use some of these items, the directive file can be tweaked to remove them. For example, if you don’t use time and expense logs, we can remove them from the directive file. That way DIET doesn’t need to even look for them, since it would never find any. This is purely a performance tweak though.
In addition, if you’re like most Clarify/Dovetail customers, you’ve customized, likely adding additional tables. So the directive file can be edited to include these additional custom tables as well.
Once the cases have been purged, then we can purge the customer (contact) record. We need to get rid of the cases first, then the contact. The directive file for purging contacts says to STOP if the contact has any cases, as we don’t want to end up with cases related to a non-existent contact, thus ending up with our data in a bad state. These built-in safeguards help protect the integrity of your data.
Purge Cases
Here’s an example of where I first purge all of the cases for a contact, and then purge the contact itself.

Purge Cases with DIET
Notice that we purged 353 cases, but the total number of records was over 11,000. All in 22 seconds. (and that’s without any tweaks or optimizations of the directives file)
Purge Contact

Purge Contact with DIET
Then we purge the contact.
Just 1 contact record (as expected), but a lot of act_entries. 102 total records in less than a second.
Redacting with SQL
Rather than deleting the data, we can redact any fields that may contain sensitive information. This allows us to keep the case intact – which is useful for reporting and history. We can see that the case exists, its case type, when it was created and closed, etc. But we’ll redact any sensitive information.
Unlike SaaS applications, Clarify/Dovetail customers have full access to the underlying database – which means we can take advantage of native database tools. Although in this case, I don’t think we need super-fancy tools – some good old-fashioned SQL will do the trick.
The hard part here is determining what you need to redact. We can certainly offer some suggestions for baseline Clarify/Dovetail data, but as the keeper of your system and data, you may need to do some auditing of your system to see where else you may have identifying customer data. For example, we’ll likely want to redact:
- contact name, phone number, email address
- contact notes
- case title
- case history
- case notes
- case phone notes
- case email logs
- case research logs
- close case logs
- etc.
A case, in its normal state
Normal Case
The same case, after being redacted

Redacted Case
And the contact, redacted
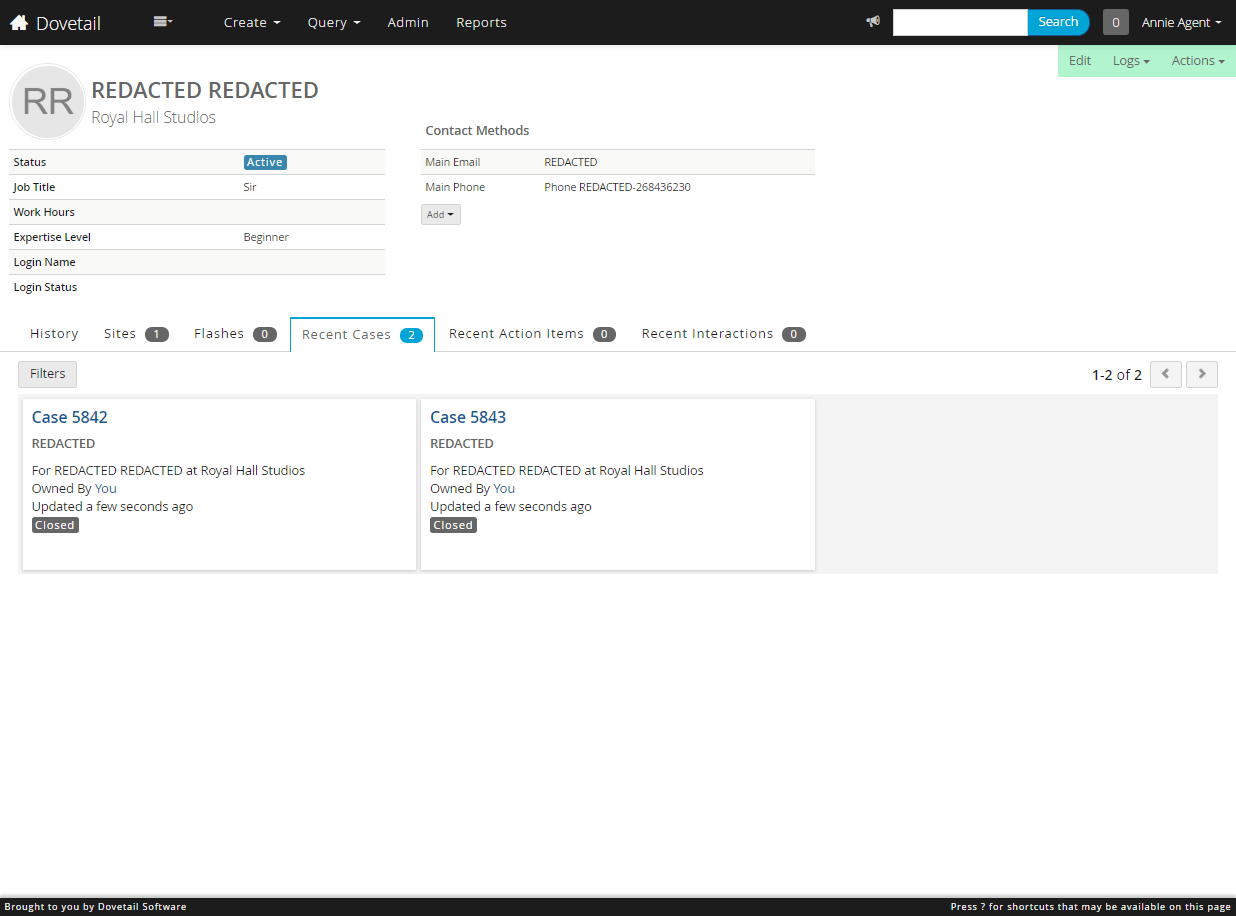
Redacted Contact
Example SQL
Here’s the SQL script that I used to redact a contact and their cases. If you want to do something similar, this script may be a good starting point.
Track and Automate these Requests
What if you wanted to track and automate this more? Just kicking around a few ideas here:
- When a new GDPR request comes in, create an Action Item with a type of GDPR and relate to the contact.
- Dispatch to GDPR Request queue
- Accept and Change the Status to Approved.
Create a new Powershell script
- finds any GDPR action items with a status of Approved
- maybe we want a delay, so we only look for those action items that are more than 30 days old
- for each one, we run either our SQL script or DIET purge commands
- log a note to the action item, saying that the purge or redaction happened
- close the action item
Create a Nightly Scheduled Task that runs the above Powershell script
Much of this mimics what I covered in a previous post: Automatically Scheduling and Tracking Work Items
Obviously, this is just some ideas. I’d probably see how many of these requests actually come in, before adding a lot of scripting and automation around the process. But, I do really like the idea of tracking these requests by an Action Item, even without the scripting and automation. This provides some history and visibility into how often these types of requests come in.
Wrap Up
With either of the above approaches (purge or redact), there is a bit of work to do, but I don’t think it’s a huge task.
- Determine your preferred approach – delete or redact data
- Determine where you may have identifying customer data (including customizations)
- Starting with either of the above technical approaches, tweak for your specific needs
The good thing is that once you’ve done this work once, it’s re-usable for future Right to be Forgotten requests.
And if you need some assistance, we’re happy to be that trusted partner and guide by your side.
